



Beyinlerimiz, kalabalık bir kahve dükkanı ya da kalabalık bir şehir caddesi gibi gürültülü bir ortamda tek tek sesler seçmek için olağanüstü bir yeteneğe sahiptir.
Bu, en gelişmiş işitme cihazlarının bile ulaşmaya çalıştığı bir performans.
Ancak şimdi Columbia mühendisleri, beynin birçok kişiden herhangi birine ait olan sesi algılamak ve büyütmek için doğal beyin yeteneklerini taklit eden deneysel bir teknolojiyi duyurdular.
Yapay zeka ile güçlendirilen bu beyin kontrollü işitme cihazı, kullanıcının beyin dalgalarını izleyen ve odaklanmak istedikleri sesi artıran otomatik bir filtre görevi görmekte
Gelişme henüz erken aşamalarında olmasına rağmen, teknoloji; kullanıcıların etraflarındaki insanlarla sorunsuz ve verimli bir şekilde konuşmalarını sağlayacak daha iyileştirilmiş işitme cihazlarına doğru atılmış önemli bir adım olarak kabul ediliyor.
Bu başarı, 15 Mayıs günü Science Advances’te yayınlandı

Makalenin kıdemli yazarı ve Columbia’daki Mortimer B. Zuckerman Zihin Beyin Davranışları enstitüsünde doktora araştırmacısı olan Nima Mesgarani, “Sesi işleyen beyin alanı olağanüstü derecede hassas ve güçlü; bir sesi diğerlerinden daha fazla ve görünüşte zahmetsizce yükseltebiliyor” diyor.
“Beynin gücünden yararlanan bir cihaz yaratarak, çalışmamızın dünya çapında yüz milyonlarca işitme engelli insanın, arkadaşları ve aileleri kadar kolay iletişim kurmasını sağlayan teknolojik gelişmelere yol açacağını umuyoruz.”
Kokteyl Partisi Problemi

Modern işitme cihazları, konuşma sırasında belirli arka plan gürültüsü türlerini bastırırken aynı zamanda konuşmayı güçlendirme konusunda mükemmeldirler. Ancak, bireysel bir sesin düzeyini benzer diğerlerine göre artırmak için önemli bir mücadele söz konusudur. Bilim adamları buna, yüksek sesli partilerde bir araya gelen seslerin kakofonisinden adını alan “kokteyl partisi problemi” diyorlar.
Columbia Mühendislik’te Elektrik Mühendisliği bölümünde Doçent olan Dr. Mesgarani, “Partiler gibi kalabalık yerlerde işitme cihazlarının aynı anda tüm konuşmacıları yükseltme eğiliminde olduğunu” söyledi.
“Bu, kullanıcının etkili bir şekilde konuşma yeteneğini önemli ölçüde engelliyor, hatta temelde onları çevrelerindeki insanlardan izole ediyor.”
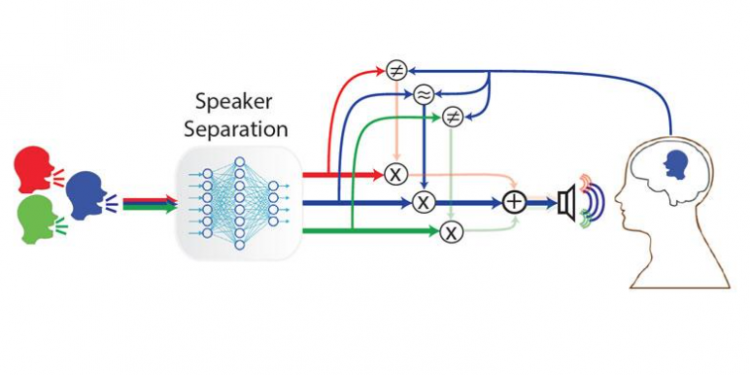
Columbia ekibinin geliştirdiği beyin kontrollü işitme cihazı ise çok farklı. Cihaz mikrofonlar gibi yalnızca harici ses amplifikatörlerine güvenmek yerine, dinleyicinin kendi beyin dalgalarını da izliyor

Mesgarani, “Bir süre önce, iki kişi birbiriyle konuştuğunda, konuşmacının beyin dalgalarının dinleyicinin beyin dalgalarına benzemeye başladığını keşfettik” dedi.
Bu bilgiyi kullanan ekip, güçlü konuşma ayrıştırma algoritmalarını; sinir ağları ve beynin doğal hesaplama yeteneklerini taklit eden karmaşık matematiksel modeller ile birleştirdi.
Öncelikle konuşmacıların seslerini bir gruptan ayıran ve daha sonra her konuşmacının sesini dinleyerek kişinin beyin dalgalarıyla karşılaştıran bir sistem yarattılar.
Böylece ses düzeni dinleyicinin beyin dalgalarına en yakın olan konuşmacının sesine odaklanılarak o ses diğerlerine göre ön plana çıkacak şekilde yükseltilir.
Araştırmacılar, bu sistemin daha önceki eski bir versiyonunu 2017’de, umut verici olmakla birlikte, önemli bir sınırlamaya sahip olarak yayınlamışlardı: Ancak sistemin belirli konuşmacıları tanımak için batan yorumlanması gerekiyordu.
Mesgarani, “Ailenizle bir restorandaysanız, bu cihaz sizin için bu sesleri tanır ve çözer” dedi. “Ancak garson gibi yeni bir kişi gelir gelmez, sistem başarısız olur.”
Bugün yaşanan gelişme bu sorunu büyük ölçüde çözüyor.
Asıl algoritmalarını geliştirmek için Columbia Technology Ventures’tan fon alan Dr. Mesgarani ve baş yazarlar Cong Han ve Dr. James O’Sullivan, dinleyicinin karşılaştığı herhangi bir potansiyel konuşmacıya genelleştirilebilecek daha sofistike bir model oluşturmak için derin sinir ağlarının gücünü kullandılar.
Mesgarani, “Son aldığımız sonuç, aslında önceki sürümlere benzer şekilde çalışan bir konuşma ayrıştırma algoritması. Ancak önemli bir iyileştirme eklentisi ile…” dedi.
“Algoritma herhangi bir sesi tanıyabilir ve çözebilir, bir yarasanın sesini bile.”

Algoritmanın etkinliğini test etmek için, araştırmacılar, Northwell Sağlık Nöroloji ve Nöroşirürji Enstitüsü’nde (Northwell Health Institute for Neurology and Neurosurgery) bir beyin cerrahı olan, makalenin yazarlarından Dr. Ashesh Dinesh Mehta ile birlikte çalıştılar.
Mehta, bazıları düzenli ameliyatlar geçirmesi gereken epilepsi hastalarını tedavi eden bir hekim.
Mesgarani, “Bu hastalar, beyin dalgaları doğrudan hasta beyinlerine yerleştirilen elektrotlar aracılığıyla izlenirken farklı konuşmacıları dinlemek için gönüllü oldular” dedi.
“Sonra yeni geliştirilen algoritmayı bu verilere uyguladık.”
Takımın algoritması, hastaların daha önce duymadıkları farklı konuşmacıları dinlerken onların dikkatini takip etti.

Bir hasta bir konuşmacıya odaklandığında, sistem otomatik olarak bu sesi yükseltti. Dikkatleri farklı bir konuşmacıya geçtiğinde ise, ses seviyesi bu değişimi yansıtacak şekilde tekrar değişti.
Aldıkları başarılı sonuçlar ile cesaret toplayan araştırmacılar, şimdi bu prototipin kafa derisine ya da kulak çevresine dışarıdan yerleştirilebilecek, “invazif olmayan” bir cihaza nasıl dönüştürüleceğini araştırıyorlar.
Ayrıca, algoritmayı daha geniş bir ortam aralığında çalışabilmesi için daha da geliştirmeyi ve iyileştirmeyi umuyorlar.
Etkili bir gerçek hayat uygulaması için kapı aralandı
Mesgarani, “Sistemi şimdiye kadar sadece iç ortamlarda test ettik” dedi. “Ancak, yoğun bir şehir caddesinde ya da gürültülü bir restoranda da çalışabilmesini sağlamak istiyoruz. Böylece kullanıcılar nereye giderse gitsinler, dünyayı ve etraflarındaki insanları tam olarak deneyimleyebilecekler.”
Bu çalışmaya katkıda bulunan diğer isimler arasında; Yi Luo ve Dr. Jose Herrero de bulunmaktadır.
Bu araştırma Ulusal Sağlık Enstitüleri (National Institutes of Health) (NIDCD-DC014279), Ulusal Ruh Sağlığı Enstitüsü (National Institute of Mental Health) (R21MH114166), Pew Charitable Trusts, Biyomedikal Bilimler ve Columbia Teknoloji Girişimleri Pew Scholars Programı tarafından desteklenmiştir.
Çalışmanın orijinaline aşağıdaki bağlantıdan ulaşabilirsiniz
Cong Han, James O’Sullivan, Yi Luo, Jose Herrero, Ashesh D. Mehta, Nima Mesgarani. Speaker-independent auditory attention decoding without access to clean speech sources. Science Advances, 2019; 5 (5): eaav6134 DOI: 10.1126/sciadv.aav6134




























